


Could the Universe Be Infinite?
The universe has fascinated humans for millennia, stretching our imagination beyond everyday…
The universe has fascinated humans for millennia, stretching our imagination beyond everyday…

The universe is filled of galaxies with vast collections of stars, gas,…

Over the past few decades the idea of exoplanet missions astronomy has…

The discovery of the most distant galaxy ever observed represents a monumental…
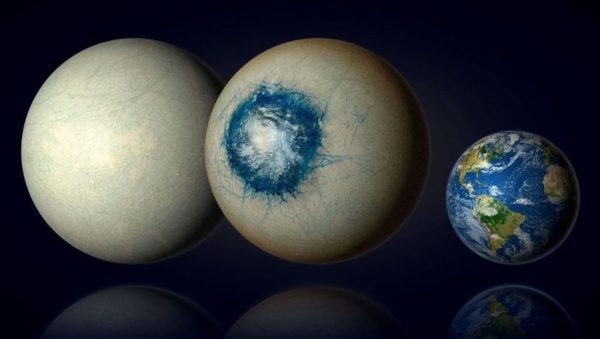
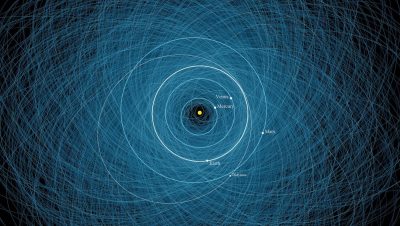
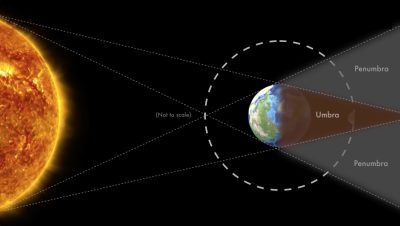
The Solar System is far more bizarre than early astronomers ever imagined.…

For thousands of years, humans have looked up at the night sky…

Mars has fascinated humanity for centuries. Once imagined as a world of…

Meteor showers are among the most spectacular and accessible astronomical events visible…

The night sky is filled with wonders, from shimmering stars to dazzling…

Variable stars the night sky may appear calm and unchanging, but careful…

Cycle of Stars are the fundamental engines of the universe. They produce…

Satellites have become one of the most critical infrastructures of modern civilization.…